ZPFS简介 ZPFS为完全兼容posix语义(操作方式与本地文件系统一致)的并行文件系统,定位为追求数据&&元数据读写高吞吐,低延迟以及数据容量弹性平滑扩缩容的高性能存储产品。
ZPFS支持存储空间的平滑扩容、数据&&元数据访问性能的平滑扩容,并提供可完全兼容posix语义的Linux系统内核客户端,在完全支持多客户端缓存数据一致性的前提下,可如使用本地文件系统一样,有效利用本机page cache进行访问加速。
ZPFS可支持千亿级文件数、EB级别数据,千亿级日均元数据服务器访问次数,百万级活跃客户端数。
基本功能
- 容量空间可平滑扩容
- 数据/元数据性能可平滑扩展(数据服务器/元数据服务器可平滑扩容)
- 内核模块客户端,完全兼容posix语义
- 支持多客户端数据缓存一致性
- 支持按文件夹设置文件数及数据容量quota
- 支持文件锁
典型优势
- 完全支持posix语义,支持多客户端数据缓存一致性
- 客户端数据读写可打满网卡带宽(数十GB/s吞吐)
- 元数据读写性能在操作对象为文件时,有较大优势海量文件
- 全对称的元数据服务器架构,单文件系统支持千亿级文件,百万级元数据OPS能力
- 可按目录鉴权,数据私密性有保障
- 代码可控,问题可追溯,方便开发满足定制需求
- 性能和容量均可平滑扩展
- 可为重点目录划分专有mds,保障高优数据性能
大模型景下使用示意图
注:zpfs为兼容posix语义的并行文件系统,可适用于任何多客户端对海量数据共享存取有要求的场景。这里仅用大模型/AI场景全生命周期举例。
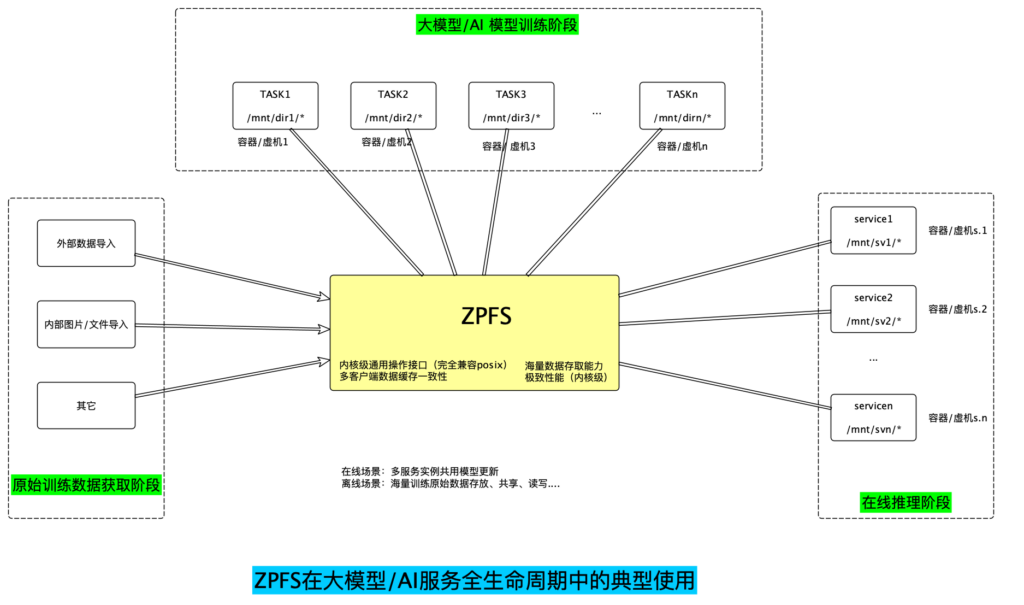
ZPFS可以在AI训练的不同阶段发挥重要的作用:
- 数据准备阶段
在AI训练的准备阶段,需要收集、清洗和标注大量数据。ZPFS提供高吞吐量和低延迟的I/O性能,加速数据准备过程;同时由于其高可拓展性,可以存储 EB级别的数据集支持超大规模AI训练。
- 模型训练及验证阶段
在模型训练阶段,需要对预处理后的大量数据进行迭代计算以及checkpoint的保存和加载。在这个过程中,ZPFS允许在多个GPU或CPU节点之间共享数据集,以支持大规模并行训练作业。由于AI训练中可能需要频繁地随机读写小文件(如模型参数、梯度更新等),ZPFS优化了小文件访问性能来支持这种访问模式。
在模型验证阶段,模型通过使用未见过的数据来测试其准确性和泛化能力。ZPFS的高性能支持快速加载数据以评估模型表现。
- 模型部署与推理阶段
ZPFS可以作为存储后端来存储模型和数据,支持推理服务的快速启动。