IDC资源管理与监控告警平台是一套专为现代数据中心(IDC)打造的统一化、智能化运维管理中枢。该平台打破了传统数据中心物理资产管理与实时状态监控之间的信息孤岛,将“静态的资产与流程管理”与“动态的运行状态与告警监控”深度融合。
平台由两大核心子系统构成:IDC资源管理平台与IDC监控告警平台。旨在为企业提供从设备入库、上架、网络连线、日常监控、故障工单处理到计费下架的全生命周期闭环管理,全面提升数据中心运维效率,保障业务的高可用性与SLA达标率。
核心功能模块一:IDC资源管理平台
资源管理平台是数据中心的“骨架”,负责梳理和记录所有物理与逻辑资产,并规范化运维协作流程。
1. 细粒度资产与拓扑管理
- 服务器资产管理:提供全局服务器台账,支持按SN码、IP、机房等条件快速检索。资产详情深度涵盖CPU、内存、硬盘、GPU、电源、网卡及所在机架U位等精确配置信息。
- 网络设备管理:全量管理交换机、路由器等网络设备状态与角色(如GS0/GS1),并自动追踪网络连接详情,包括服务器BMC/网口与交换机端口的级联拓扑关系。
- 机房/机架可视化呈现:支持机架位列表与机架位可视化视图(U位图)。运维人员可直观看到每个机柜的空闲/占用状态、设备所处U位及总功耗限制,极大地方便了现场上架规划。
2. 资产全生命周期流水线
- 流程化出入库:对资产的出库、入库、上架、下架流程进行严密的工单流转记录。支持追踪设备到达时间、当前环节、处理人及操作历史,确保账物相符,资产变动有迹可循。
3. 故障处理与SLA管理闭环
- 智能故障追踪:通过故障列表统一管理所有异常。故障详情页提供直观的故障根因诊断拓扑与处理时间轴(已创建->待处理->处理中->已处理),并记录详细的排障日志与维修换件记录。
- 多维故障看板:图形化展示设备平均响应时间、平均修复时间(MTTR)、故障时长及按不同类型(如主板、GPU、网卡、风扇等)统计的故障分布,辅助管理层进行质量复盘。
- SLA实时看板:根据业务等级定义SLA数据,实时核算各机架、各维度的在线时长、不可用时长及SLA扣除情况,量化数据中心服务质量。
4. 账单与资源开通管理
- 资源计费化:支持对裸金属、云主机等不同类型资源的开通记录进行追踪。提供详细的账单明细,涵盖实例ID、所属产品分类、SKU及费用,方便跨部门进行成本核算与分摊。
5. 一站式运维工作台
- 工单与值班协同:提供标准化的运维工单系统(我的待办、已办、创建工单),支持工单流转。内置日历式值班表管理,明确每日/时段的责任人,确保7×24小时运维响应无缝衔接。
核心功能模块二:IDC监控告警平台
监控告警平台是数据中心的“神经系统”,具备极强的可观测性与敏捷的异常预警能力。
1. 行业标准的数据接入底座
- 平台采用行业领先的 Prometheus 或 VictoriaMetrics 时序数据库进行数据存储。
- 支持通用的 PromQL 查询语言,兼容Push(推)与Pull(拉)双向数据同步方式,具备极强的开放性与扩展性。
2. 全栈监控大盘(Dashboards)
平台内置丰富的Grafana风格可视化仪表盘,覆盖从底层硬件到基础软件的全栈监控:
- GPU与服务器硬件监控:深度监控GPU的DRAM温度、功耗限制、利用率等;实时获取服务器IPMI/BMC传感器数据,包括电源状态、风扇转速、主板各部件温度与电压等。
- 网络与交换机监控:直观展示交换机端口状态、LLDP对端设备信息、BGP Peer连通性状态图表,以及上下行流量趋势。
- 存储系统监控:
- GPFS文件存储:监控集群状态、节点存活、工作线程数、挂起线程等核心指标。
- OSS对象存储:全面监控OSD状态、健康度、IO吞吐、磁盘(NVMe/HDD/SSD)容量及损坏情况。
- 网络设备与中间件:支持对 F5负载均衡设备(流量、连接数、Pool状态)以及 Harbor镜像仓库(核心组件健康度、Repo容量、请求速率)的实时观测。
3. 敏捷灵活的告警与通知规则
- 告警规则配置:运维人员可通过可视化界面或原生PromQL语句配置告警条件(如
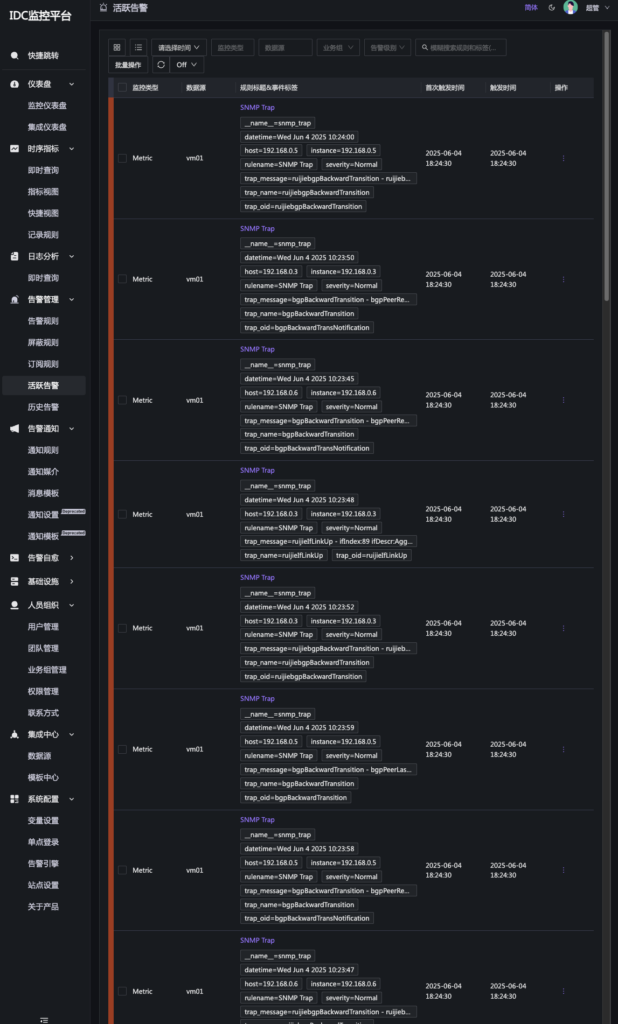
avg(1 - avg_over_time(...)) > 0.1)。支持设置不同严重级别(Critical/Warning/Info)及持续时长触发条件。 - 活跃告警管理:实时汇聚当前未恢复的告警事件(如SNMP Trap、链路Down、BGP断开等),并支持告警压制与聚合显示,减少“告警风暴”。
- 通知路由与模板:灵活的通知规则配置,支持根据告警标签(业务组、严重程度)自动路由派发。支持邮件、企业通讯工具等多种接收媒介,确保关键告警精准触达一线排障团队(Ops邮件组/值班人员)。
产品的核心技术与业务价值
- 所见即所得的数字孪生
将抽象的IT资产转化为可视化的机架U位图和网络拓扑图,让数据中心物理空间管理一目了然,降低了新人的学习成本和人为操作失误。 - 打破监控与资产的边界
传统模式下,监控系统报警只显示IP,运维人员需跨系统查询物理位置。本平台将告警数据与静态资产信息深度绑定,收到告警的同时即可定位设备所在的机房、机柜及U位,极大缩短了故障排查时间(MTTR)。 - 拥抱云原生监控生态
原生支持Prometheus/VictoriaMetrics体系,完美契合当前云原生环境。不仅能监控物理机硬件,还能轻松拓展至Kubernetes集群及云上资源的统一监控。 - 数据驱动的精细化运营
通过SLA看板、故障类型统计和账单明细,将数据中心从“黑盒运营”升级为“数据驱动”。管理层可以根据故障率决定硬件采购策略,根据计费明细优化部门IT成本。